Базовое понимание слэшинга и его мотивация
Если упростить, слэшинг в proof of stake что это: это механика наказания валидаторов за поведение, которое подрывает безопасность сети. Протокол фиксирует нарушения, от «мягких» (долгое оффлайн‑состояние) до «жёстких» (двойная подпись блока или атака на финальность), и автоматически сжигает часть стейка. Идея в том, что валидатор ставит под угрозу собственные деньги, когда пытается обмануть сеть. В отличие от PoW, где вы просто тратите электричество, здесь риск мгновенный и капитальный, поэтому ошибки конфигурации становятся не менее опасными, чем злой умысел.
Какие риски реально несёт валидатор
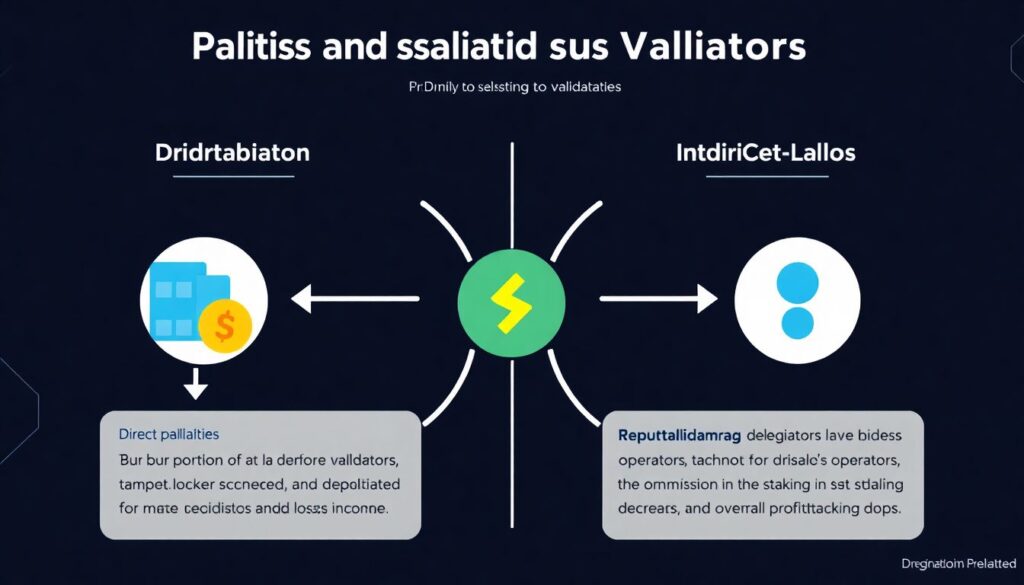
Штрафы и слэшинг валидаторов в криптовалюте делятся на прямые и косвенные. Прямые — это сжигание доли стейка и временный бан, когда вы не можете валидировать и теряете доход. Косвенные — репутационные потери: делегаторы уходят к более надёжным операторам, комиссия в стейк‑пуле падает, а окупаемость инфраструктуры ухудшается. Парадокс в том, что зачастую валидатор «ловит» слэшинг не из‑за злонамеренных действий, а из‑за кривого DevOps: дублирующиеся ноды, незащищённые ключи, неаккуратные обновления или эксперименты в проде без тестовой среды.
Необходимые инструменты и базовая инфраструктура
Чтобы настройка и защита валидатора от слэшинга не превратились в хаос, нужно минимальное, но продуманное окружение. Во‑первых, выделенный сервер или VPS с предсказуемым IOPS и резервным питанием, плюс отдельная машина под sentry‑ноды, чтобы не светить основной валидатор наружу. Во‑вторых, модульный набор: менеджер сервисов (systemd), инструмент оркестрации (Docker или Ansible), централизованный логгер (Promtail, Vector) и метрики (Prometheus + Grafana). В‑третьих, хранилище ключей: аппаратные кошельки, HSM или хотя бы защищённый раздел с жёстко ограниченными правами доступа.
Поэтапный процесс безопасного развёртывания
Правильный поэтапный процесс начинается не с поднятия ноды, а с моделирования угроз. Сначала запускается полноценный стенд в тестовой сети с идентичной конфигурацией, где вы сознательно провоцируете сбои: отключаете интернет, перезагружаете сервер, ломаете диски данных. Затем выстраиваете пайплайн обновлений: CI/CD, который никогда не трогает ключи подписи и всегда делает dry‑run на тестовой ноде. Только после этого переводите проверенную конфигурацию в прод и включаете алерты по задержкам блоков, пропускам слотов и отклонениям времени системы, снижая вероятность непреднамеренного нарушения протокола.
Нестандартные подходы к снижению риска слэшинга
Если говорить о том, как избежать слэшинга валидатора в pos сети нестандартно, имеет смысл думать как SRE, а не как «криптоэнтузиаст». Во‑первых, используйте принцип chaos engineering: запланированные «аварии» раз в месяц, чтобы убедиться, что автоматическое фейловер‑переключение не создаёт двойной подписи. Во‑вторых, внедряйте policy‑as‑code — описывайте допустимые состояния инфраструктуры в виде кода и запрещайте поднятие второй активной ноды с теми же ключами. В‑третьих, применяйте «канареечные валидаторы» с малым стейком, на которых обкатываются новые версии клиента и нестандартные сетевые настройки.
Инструменты мониторинга и активной защиты
Настройка и защита валидатора от слэшинга невозможны без агрессивного мониторинга. Классика — Prometheus и Grafana с дашбордами по высоте блока, времени отклика, количеству подписи слотов и размеру мемпула. Добавьте alertmanager, шлющий уведомления в Telegram, Matrix или Slack за секунды до потенциального простоя. Для продвинутых конфигураций используйте сторонние «слэшинг‑защиты» клиента: отдельные демоны, которые отслеживают, не пытается ли другая нода подписать блок теми же ключами, и немедленно гасят дублирующий процесс. Это дешевле, чем потерять проценты от крупного стейка.
Устранение неполадок и действия после инцидента

Раздел «Устранение неполадок» критичен: после слэшинга паника только усугубит ущерб. Алгоритм такой: немедленно остановить все экземпляры валидатора с проблемными ключами, зафиксировать логи и сетевые дампы, затем поднять «холодную» резервную ноду с новым валидаторским ключом, если протокол это допускает. Параллельно анализируются причины: время системы, рассинхронизация клиентов, конфликт скриптов фейловера. Важно работать по заранее прописанному runbook, а не импровизировать: это снижает вероятность повторного слэшинга во время попытки восстановления и успокаивает делегаторов.
Обучение, аутсорс и коллективная защита
Неочевидное, но эффективное решение — не замыкаться в одиночку. Обучение и услуги по защите валидаторов от слэшинга сейчас предлагают как команды экосистем, так и независимые провайдеры: аудиты инфраструктуры, симуляции атак, разбор реальных инцидентов. Можно пойти дальше и объединиться с другими валидаторами в небольшой «операционный синдикат»: общие плейбуки, общий репозиторий Ansible‑ролей, обмен алертами о нестандартном поведении сети. Такой коллективный интеллект стоит дешевле, чем строить весь стек in‑house, и часто позволяет поймать аномалию ещё до её эскалации в реальный штраф.
Итоговый взгляд и практичный майндсет оператора

Вместо того чтобы воспринимать слэшинг как абстрактное зло, полезно принять его как часть модели риска бизнеса валидатора. Классический DevOps‑подход «поднять ноду и не трогать» здесь не работает: нужна инженерная дисциплина, тестовые среды, документированные процедуры и регулярные учения. Главное — относиться к валидатору как к высоконагруженному финансовому сервису, где каждый процент стейка под слэшингом — это реальный PnL. Тогда любые решения, от выбора дисков до политики обновлений, автоматически подстраиваются под цель: минимизировать вероятность критического нарушения протокола, а не просто «чтобы работало».

